One Billion Row Challenge in Rust
Note (2026-01-13): this post originally resided in the repository README.md and was later migrated to the blog. The publish date matches the commit of the final README.md version.
This article covers my implementation in Rust for the One Billion Row Challenge (1BRC), which tests the limits of processing one billion rows from a text file. The implementation lives in my brc-rs repository, and the challenge itself is in the original challenge repository.
The main idea is to explore program optimization through profiling and parallelism while trying to use only “Safe Rust”. Error handling in this project is intentionally minimal, and only the happy path is considered.
Challenge
The text file contains temperature values for a range of weather stations.
Each row is one measurement in the format <string: station name>;<double: measurement>, with the measurement value having exactly one fractional digit.
The following shows ten rows as an example:
Hamburg;12.0
Bulawayo;8.9
Palembang;38.8
St. John's;15.2
Cracow;12.6
Bridgetown;26.9
Istanbul;6.2
Roseau;34.4
Conakry;31.2
Istanbul;23.0The task is to write a program which reads the file, calculates the min, mean, and max temperature value per weather station, and emits the results on stdout like this
(i.e. sorted alphabetically by station name, and the result values per station in the format <min>/<mean>/<max>, rounded to one fractional digit):
{Abha=-23.0/18.0/59.2, Abidjan=-16.2/26.0/67.3, Abéché=-10.0/29.4/69.0, Accra=-10.1/26.4/66.4, Addis Ababa=-23.7/16.0/67.0, Adelaide=-27.8/17.3/58.5, ...}Optimization Results
Here is a table for a quick summary of the current progress of the optimizations.
Benchmarks and profiling results shown below are run against a measurements.txt generated with ./create_measurements.sh 1000000000, having 1 billion entries using a 10-core 14” MacBook M1 Max 32 GB.
| Optimization | Time (mean ± σ): | Improvement over previous version | Summary |
|---|---|---|---|
| Initial version | 149.403 s ± 0.452 | N/A | Naive single-core implementation with BufReader and HashMap |
| Unnecessary string allocation | 102.907 s ± 1.175 | -46.496 s (-31%) | Remove an unnecessary string allocation inside the loop |
| Iterate over string slices instead of String | 63.493 s ± 1.368 | -39.414 s (-38%) | Read the entire file into memory first, iterate over string slices, and avoid Entry API access for the hashmap |
| Improving the line parsing #1 | 55.686 s ± 1.304 | -7.807 s (-12%) | Replace str::find with a custom, problem-specific separator finder |
| Improving the line parsing #2 | 44.967 s ± 0.542 | -10.719 s (-19%) | Build a custom byte-based measurement parser on top of the previous optimization |
Use Vec<u8> everywhere instead of String | 38.470 s ± 0.485 | -6.497 s (-14%) | Save time by skipping UTF-8 validation in the hot path where text APIs are unnecessary |
| A custom hash function | 30.427 s ± 0.455 | -8.043 s (-21%) | Use a faster hash function for the hashmap |
| Custom chunked reader | 29.310 s ± 0.276 | -1.117 s (-4%) | Write a custom chunked file reader to prepare for parallelism and reduce memory allocation |
| Tweak chunk size | 28.663 s ± 0.546 | -0.647 s (-2%) | Small tweak for the fixed buffer size created in the previous optimization |
| Multithreading | 3.747 s ± 0.093 | -24.916 s (-87%) | Multithread the program to utilize all cores on the system |
Initial Version
Nothing special really, just a quick version to get things going with a HashMap<String, WeatherStationStats>.
I spent too long getting a correct implementation of the rounding calculation to pass the original test suite.
Going forward, the rounding conventions will change. The test files are generated with the initial version of this project, with only the conversion logic changed.
~/src/github/brc-rs (main*) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 149.403 s ± 0.452 s [User: 144.499 s, System: 2.486 s]
Range (min … max): 149.037 s … 150.110 s 5 runs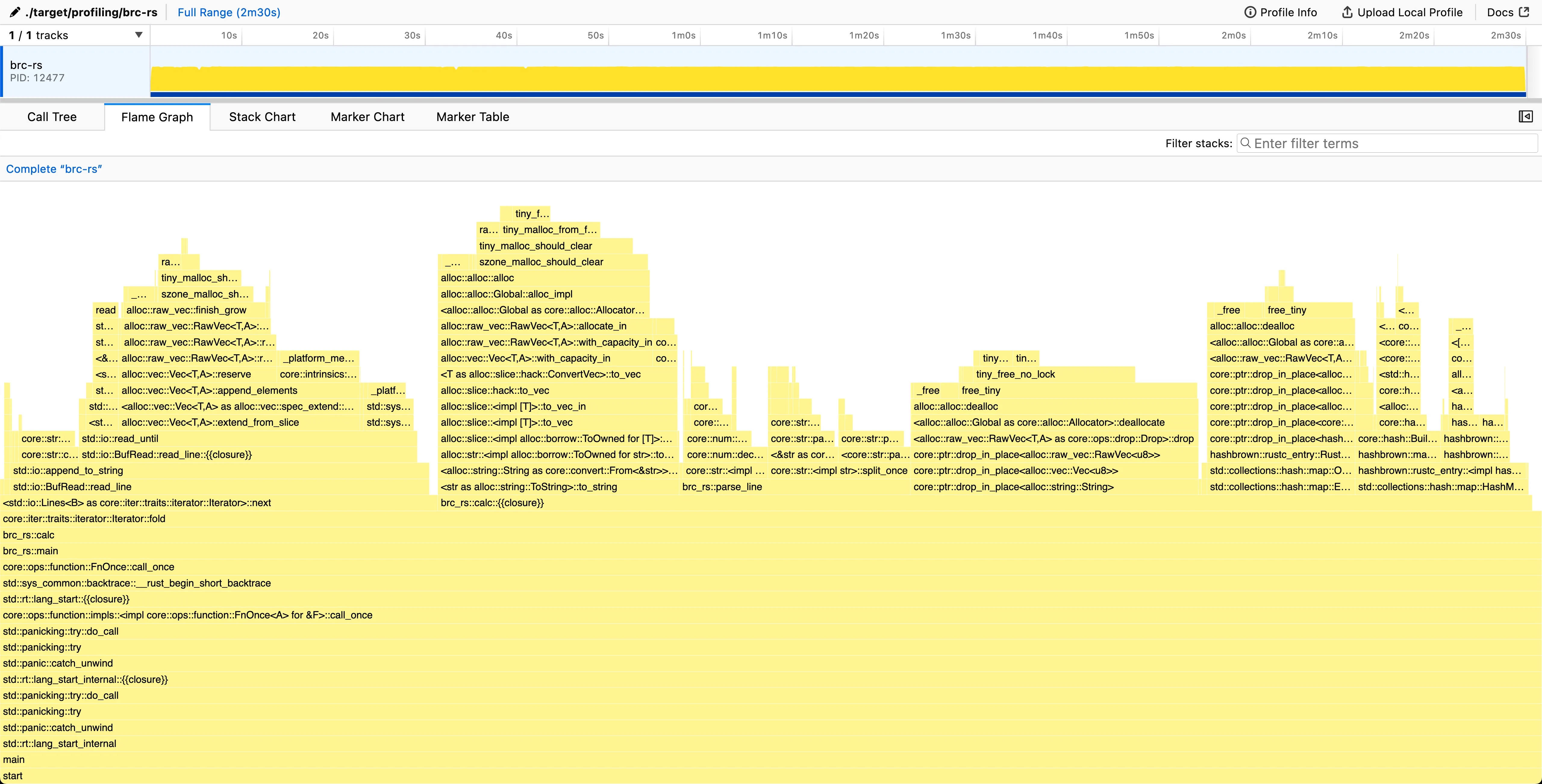
Looking at the flame graph, we spend ~30% of the time in <std::io::Lines as core::iter::traits::iterator::Iterator>::next. That is, reading the file line by line. This is most likely due to the use of BufRead::lines() for iterating the lines, as it creates a new String for each row, allocating memory. This allocation of each line separately creates unnecessary overhead, and probably should be looked into first.
Inside the calc-function we also spend 13% of the time creating strings and 17% of the time dropping Strings, freeing the allocated memory. We spend 16% in actually parsing the line, and 22% doing hashmap operations.
Unnecessary string allocation
Even though the profile indicates file reading should be addressed first, while writing the previous analysis I realized that I made a totally unnecessary string allocation inside calc.
As we already receive a String from the iterator and only pass it as a string slice to parse_line, we can instead pass ownership to parse_line and return the original line string truncated to only contain the station name.
By doing this, we can use that as the key for the hashmap instead of allocating a new string entirely for it.
~/src/github/brc-rs (main*) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 102.907 s ± 1.175 s [User: 98.842 s, System: 2.179 s]
Range (min … max): 101.440 s … 104.566 s 5 runsThis just goes to show that allocating another string unnecessarily with this amount of data has already a significant impact on performance.
Iterate over string slices instead of String
The reading of the file has grown to 44% time spent. This needs to be addressed.
Let’s first investigate the iterator performance with writing some test programs:
// test-bufread-lines.rs
use std::io::BufRead;
fn main() {
let now = std::time::Instant::now();
let f = std::fs::File::open("measurements.txt").unwrap();
let reader = std::io::BufReader::new(f);
let mut amount_read = 0;
for line in reader.lines() {
amount_read += line.unwrap().len() + 1; // add the newline character back
}
println!("reading {amount_read} bytes took {:#?}", now.elapsed());
}This program emulates the current implementation’s line iteration by using the BufRead::lines function to iterate over each line.
Note that the lines returned are all of type String underneath.
~/src/github/brc-rs (main*) » rustc -O test-bufread-lines.rs
~/src/github/brc-rs (main*) » hyperfine ./test-bufread-lines
Benchmark 1: ./test-bufread-lines
Time (mean ± σ): 55.872 s ± 0.080 s [User: 53.816 s, System: 1.860 s]
Range (min … max): 55.764 s … 56.055 s 10 runsSo 55 seconds for iterating the file line by line? That seems kind of slow. Let’s try to see if we can improve on that.
Now let’s look at the following program:
// test-read-to-string-lines.rs
use std::io::Read;
fn main() {
let now = std::time::Instant::now();
let f = std::fs::File::open("measurements.txt").unwrap();
let mut reader = std::io::BufReader::new(f);
let mut s = String::new();
reader.read_to_string(&mut s).unwrap();
let mut amount_read = 0;
for line in s.lines() {
amount_read += line.len() + 1; // add the newline character back
}
println!("reading {amount_read} bytes took {:#?}", now.elapsed());
}Instead of using BufRead::lines, here we first read the entire file into a String and then iterate over the lines with str::lines.
~/src/github/brc-rs (main*) » rustc -O test-read-to-string-lines.rs
~/src/github/brc-rs (main*) » hyperfine ./test-read-to-string-lines
Benchmark 1: ./test-read-to-string-lines
Time (mean ± σ): 19.514 s ± 0.793 s [User: 15.472 s, System: 1.311 s]
Range (min … max): 18.939 s … 21.331 s 10 runsReading the entire string first into memory results in a staggering 66% performance improvement.
The penalty coming from the BufRead::lines-iterator is that it allocates every line separately as a String.
This means on each line iteration, we allocate (and also de-allocate) memory, which causes significant overhead.
However, reading the entire file into a single String comes with a glaring drawback: the entire file will be stored in memory at once, so the memory footprint will be affected.
~/src/github/brc-rs (main*) » /usr/bin/time -l ./test-bufread-lines
reading 13795898567 bytes took 56.876117291s
--- redacted ---
1114688 peak memory footprintPeak memory footprint of ~1.1 MB when using the buffered reader.
~/src/github/brc-rs (main*) » /usr/bin/time -l ./test-read-to-string-lines
reading 13795898567 bytes took 21.289027s
--- redacted ---
13803464960 peak memory footprintThe peak memory footprint is now in the neighborhood of 13.8 GB, so a roughly 10,000x increase over using the buffered reader. This isn’t ideal and not the final solution I’d hope to achieve, but for now it’s good enough (and allowed in the original rules). Further improvements will be done later on, but for that we need to look at other parts to refactor until we can get back to this.
Now that we iterate over string slices instead of strings, we need to revert our parse_line to its previous state.
Another problem arises with the HashMap::entry() access method into the hashmap.
The function requires passing the key by value instead of reference, meaning we would need to allocate a new string for the station name on each iteration.
This would result in going back to allocating on each iteration, removing the optimization.
The Entry API in the standard library doesn’t seem to work with expensive keys
Let’s instead use HashMap::get_mut() with a match, either modifying the value or inserting a new one.
Here we limit the allocations to only occur on the inserts, and get_mut() happily takes a string slice as argument.
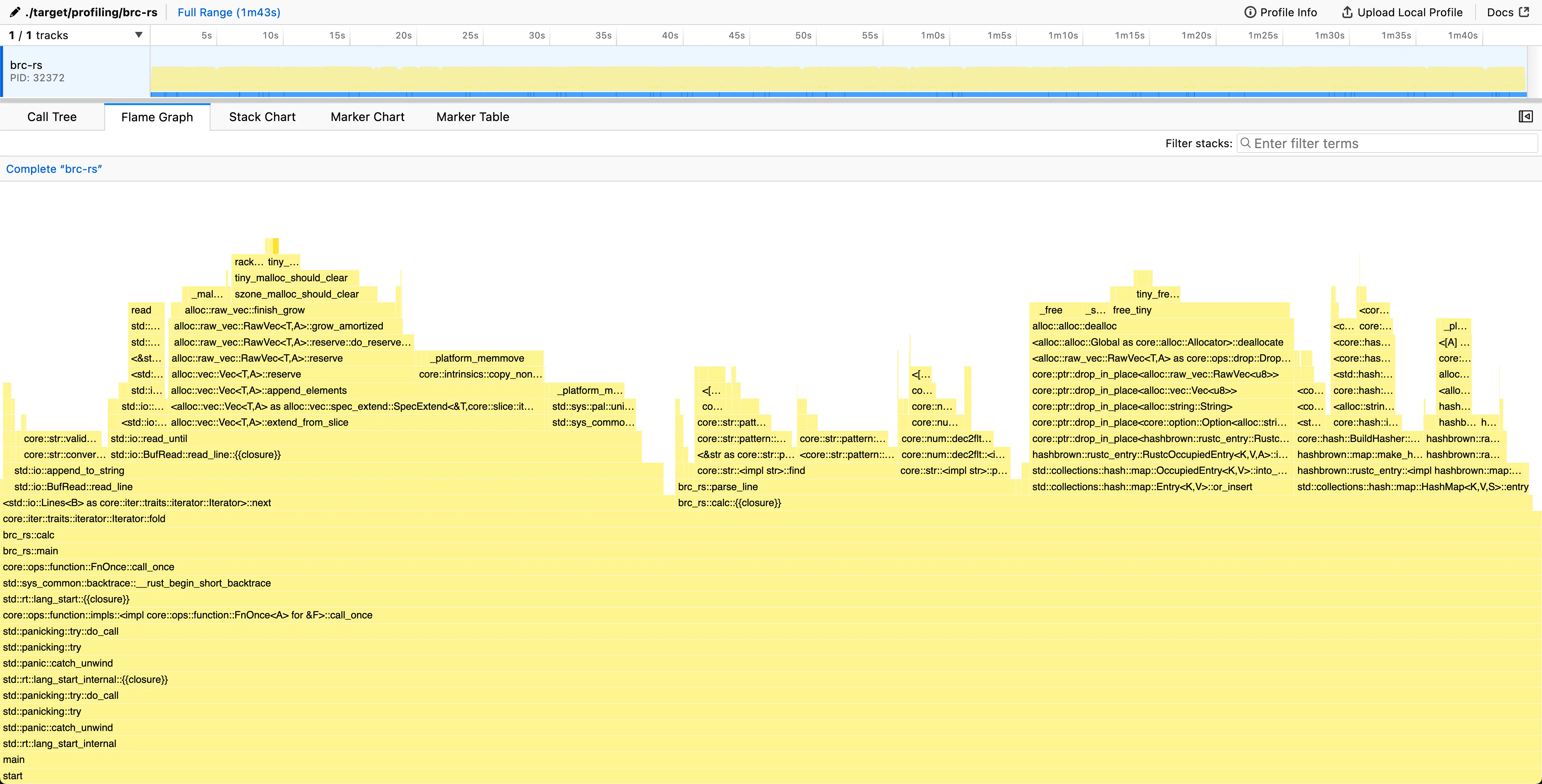
~/src/github/brc-rs (main*) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 63.493 s ± 1.368 s [User: 58.224 s, System: 2.112 s]
Range (min … max): 62.183 s … 65.675 s 5 runs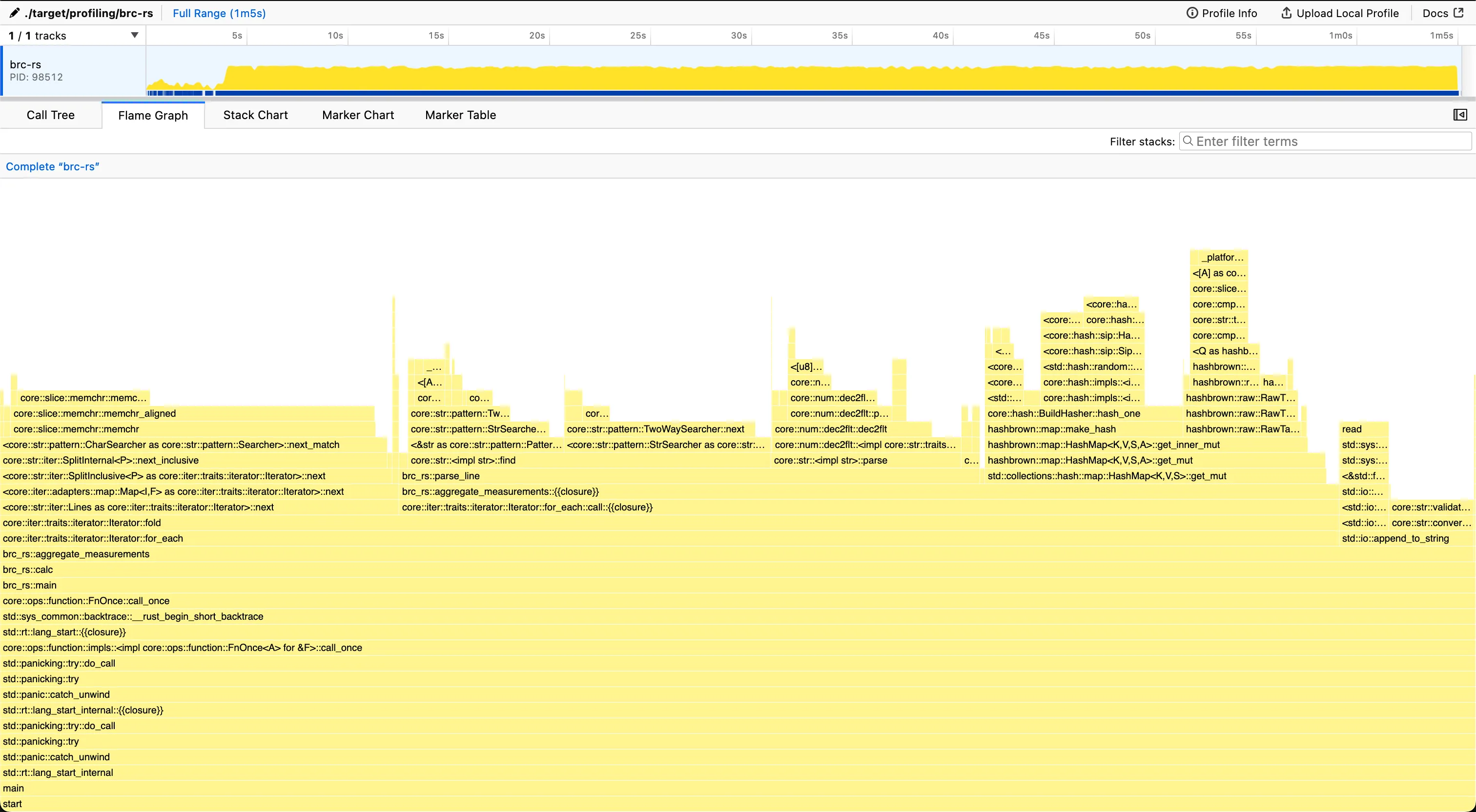
The line reading still uses quite a significant portion of the time (27% line iteration + 9% for loading the string into memory). However, it is not the biggest consumer of time anymore, which indicates we need to change our focus.
We spend 39% of the time inside parse_line(), so that is the next target.
The HashMap::get_mut() is also starting to creep up in the chart with 23% of time spent.
With parsing now dominant, the next step is to optimize separator and value extraction.
Improving line parsing
Now that we have gotten rid of most of the “free” improvements out of the way, we can start looking at actually improving the performance of the parsing logic of the lines. This section is divided in two parts; finding the data separator followed by improving the parsing logic.
Replacing str::find with a custom separator finder
Biggest share of time inside parse_line() is spent in str::find.
This is used for separating the station name from the measurement data point.
Using a generic “find from string”-function is fine for initial implementation and good for readability, but performance is being left on the table if we don’t utilize all the knowledge we have.
Reading the challenge rules, we know that the station name is a valid UTF-8 string with length varying between 1 and 100 bytes. The maximum length of the measurement data point is at most 5 characters (“-99.9”) and is always pure ASCII.
As the average length of a measurement is much smaller than the UTF-8 string, we can change our approach to start reading the line from the end. Also as the measurement is known to be pure ASCII, we can iterate over the bytes directly instead of the characters.
This makes finding the separator use at most six byte comparison operations. We could further reduce this down to three, as there is always guaranteed to be one fractional digit, a period, and a whole number, but this improvement is insignificant and we’d need to remove it anyway for the next part.
~/src/github/brc-rs (main*) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 55.686 s ± 1.304 s [User: 50.524 s, System: 2.026 s]
Range (min … max): 54.354 s … 57.095 s 5 runs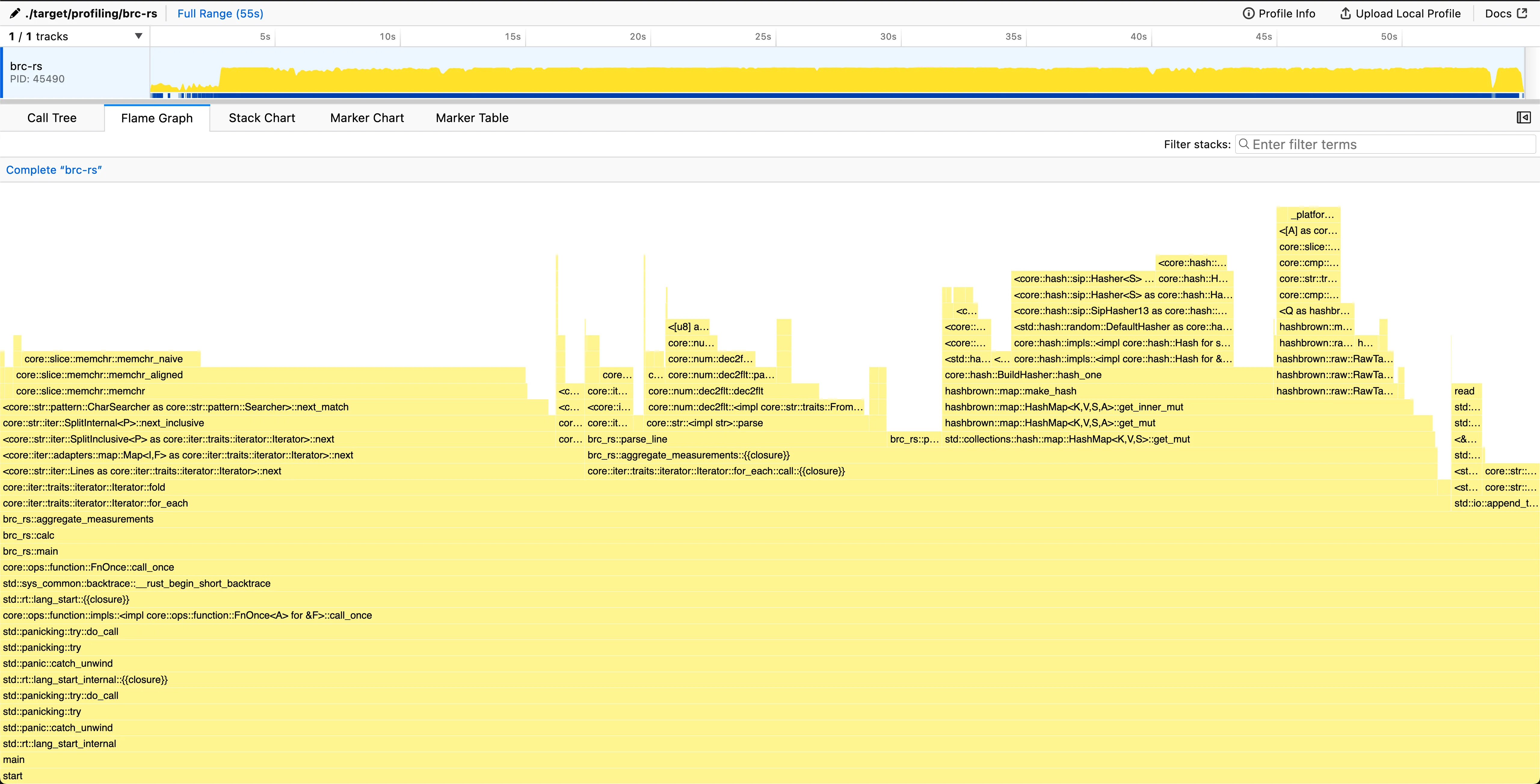
From the graph we see that parse_line() has shrunk significantly, with floating point value parsing now taking the majority of the time.
Writing a custom measurement parser
At this point we would probably start looking into replacing the standard hashmap with something custom, or revisiting line iteration again, but we’re not done improving the parse_line() function yet.
Now we’ll look at how to improve value parsing from standard f64::FromStr to something custom based on the constraints given to us.
Quick recap regarding the specification in the rules regarding the measurement data:
Temperature value: non null double between -99.9 (inclusive) and 99.9 (inclusive), always with one fractional digit
Based on this information, we always know that there is only a single fractional digit and at most two digits for the whole number part. What first comes to mind is to convert the number into a whole number entirely by shifting/removing the decimal point from the number, and converting back to decimal in the end. This would allow us to do all the math with 64-bit integers instead of floating point numbers. On M1 silicon this seems faster, at least according to this Stack Overflow post. More notably, writing a custom parser for an integer is much more straightforward than doing the same for a float.
However, we are immediately met with an issue: we have a string slice, so how should we create the integer efficiently? One option would be to str::replace the . and then call i64::FromStr, but that would decimate performance because str::replace returns a String and therefore allocates. We already established in previous sections that this is expensive. Swapping the fractional digit and . in place is also not possible here, because that would require a &mut str, which the line iterator does not provide.
The previous section hinted at the solution. When we iterate bytes in reverse to find the semicolon that separates station name and measurement, we also pass through all bytes of the measurement itself. We can parse those bytes directly by converting each ASCII digit into a number and multiplying by 10 and 100 to shift whole-number digits in base ten. ASCII conversion is straightforward here: subtract 48 (or b'0' in Rust) from each byte, because digits 0 to 9 are contiguous in the ASCII table.
~/src/github/brc-rs (main*) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 44.967 s ± 0.542 s [User: 39.777 s, System: 1.882 s]
Range (min … max): 44.196 s … 45.416 s 5 runs After these improvements, we reduced time spent in
After these improvements, we reduced time spent in parse_line() from 39% to 14%.
At this point, the next opportunities are line iteration and hashmap operations.
Using Vec<u8> instead of String
Now that our parse_line() function is fully custom and works directly on bytes, there is no need to use strings anymore.
On the right corner of the previous flamegraph, we can see that we spend around 5% of the program in something called core::str::validations:run_utf8_validation.
This is UTF-8 string validation. As all String values must be valid UTF-8 in Rust, it always runs when not using unsafe.
As none of the code below relies on string slices anymore, we can get an easy win by converting all String values and string slices used in aggregate_measurements() to Vec<u8> and byte slices respectively.
Our hashmap also changes its signature to HashMap<Vec<u8>, WeatherStationStats>, and some string conversion is required in final result formatting, but that takes insignificant time outside the hot path.
~/src/github/brc-rs (main\*) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 38.470 s ± 0.485 s [User: 33.038 s, System: 2.247 s]
Range (min … max): 37.837 s … 38.919 s 5 runs The line iterator is still taking up 40% of all the time spent in the program, but optimization beyond this point seems quite difficult, and easier gains can be found elsewhere.
Replacing the standard hashmap implementation seems like the logical step forward.
The line iterator is still taking up 40% of all the time spent in the program, but optimization beyond this point seems quite difficult, and easier gains can be found elsewhere.
Replacing the standard hashmap implementation seems like the logical step forward.
A custom hash function
Currently, 23% of all time spent is in hashbrown::map::make_hash. This is the conversion of a hashable type (in this case &[u8]) to a hash enclosed in a u64.
This value can then be used to find the value from the underlying data structure, that is hidden from the end-user of a hashmap. Regardless, this is quite slow and can be improved.
Hashmaps in Rust need to be provided a struct implementing the trait BuildHasher.
As one would guess, its task is to build Hashers.
One is built each time a new hash needs to be calculated.
Hashers built by the same builder instance must always produce the same output for the same input.
The default BuildHasher that is the default for HashMap is RandomState.
For each RandomState, a new randomized pair of keys is built that it then passes to its hashers during construction.
These randomized keys are there to prevent Hash DoS attacks from malicious users.
Given that our input is not malicious, we don’t seem to benefit from the randomized seeding of the HashMap, so we can instead look for better performance instead.
After looking around into alternatives, I found rustc_hash with quite a nice Hasher-implementation.
Originally based on Firefox’s hashing algorithm, this crate is used in rustc due to its performance over the standard library.
The characteristics of a compiler make it less susceptible to Hash DoS attacks.
I took the Hasher implementation from that crate and integrated it only with u64 instead of the original usize.
This might technically bend the rules a bit, but there are still no runtime dependencies in the benchmarked solution binary. The only external crates are rand and rand_distr, used for the measurement generation binary.
~/src/github/brc-rs (main*) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 30.427 s ± 0.455 s [User: 25.203 s, System: 1.876 s]
Range (min … max): 29.945 s … 31.111 s 5 runs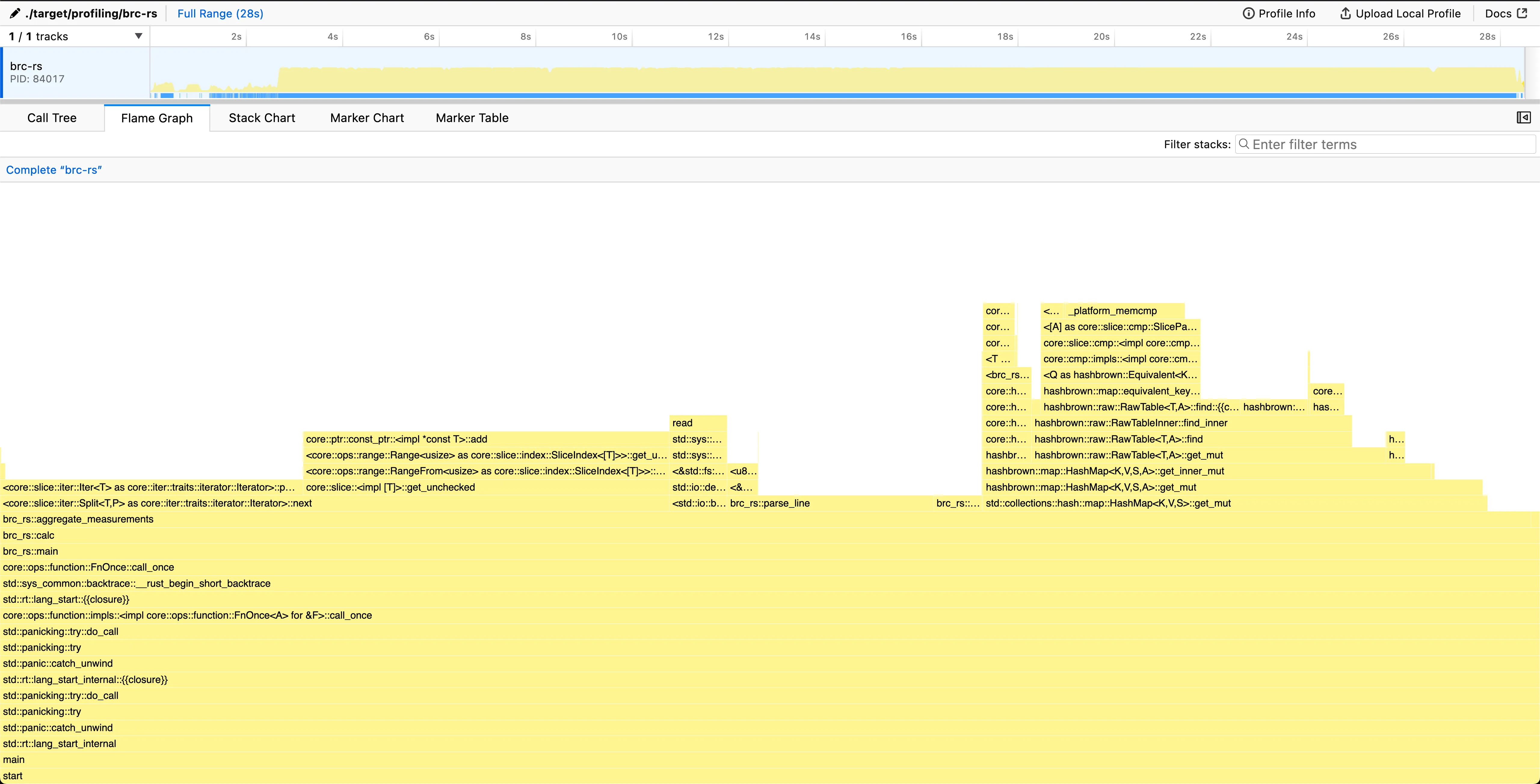
Chunked reader to reduce memory footprint & prepare for parallelism
In section Iterate over string slices instead of String, we moved from reading the file line by line to loading the entire file first into memory instead. This caused our memory usage to increase to a staggering 13 GB, but gained performance by avoiding constant allocation and deallocation of smaller strings.
However, as mentioned in the section, this was not the optimal/end result we wanted to achieve, and now it’s time to go back to that. Allocating 13 GB and reading the entire file is still inefficient, as we are blocked from doing anything for the whole duration of loading the file into memory. Looking at the previous flame graph, loading the file seems to take around 2-3 seconds. Ideally, we’d like I/O to be distributed evenly across execution.
Where this matters more is when we want to start utilizing multiple cores at once. With our current approach, when we spawn threads we’d start reading from the file system concurrently with each thread. This would put more stress on I/O, thus blocking all threads.
To prevent the 13 GB allocation and prepare for parallelism, it’s time to ditch BufReader and write our own buffered reader.
The concept is exactly the same as what BufReader does under the hood, but with us having full control of the underlying buffer and reading from the file.
We’ll create a fixed-size byte slice to act as our “buffer”, where we’ll read bytes directly from the file handle (or anything that implements the Read trait).
The complexity in this approach is handling the case when we hit the end of the currently read buffer. As we read a fixed amount in bytes at once, there is no guarantee that we read full lines. The last characters in the end of our buffer are most likely a start of a new line, but not a complete one.
To address this, we need to do the following:
- Fill the buffer in its entirety
- Parse the lines, keeping track of how many bytes we have read from the buffer.
- Do this until we hit the point where we do not find a newline character.
- Copy the remaining characters from the end to the start of the buffer.
- Read from the file to the buffer, but this time starting after the remaining characters we just copied.
- Repeat until we reach
EOF, then exit the loop.
When we reach EOF, the Read::read returns Ok(0), indicating that no new bytes were read. Combining with the fact that we only try reading more when we don’t have a complete line in the remaining characters, we know that there are no more lines to be parsed, and we can exit the loop.
~/src/github/brc-rs (main*) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 29.310 s ± 0.276 s [User: 27.071 s, System: 1.465 s]
Range (min … max): 29.036 s … 29.696 s 5 runsAs expected, this is not a huge single-core improvement. The main win is avoiding a contiguous 13 GB allocation.
~/src/github/brc-rs (main*) » /usr/bin/time -l target/release/brc-rs
...
29.40 real 27.21 user 1.52 sys
1261568 maximum resident set size
...
967232 peak memory footprintAs we can see, our peak memory footprint is again under 1 MB.
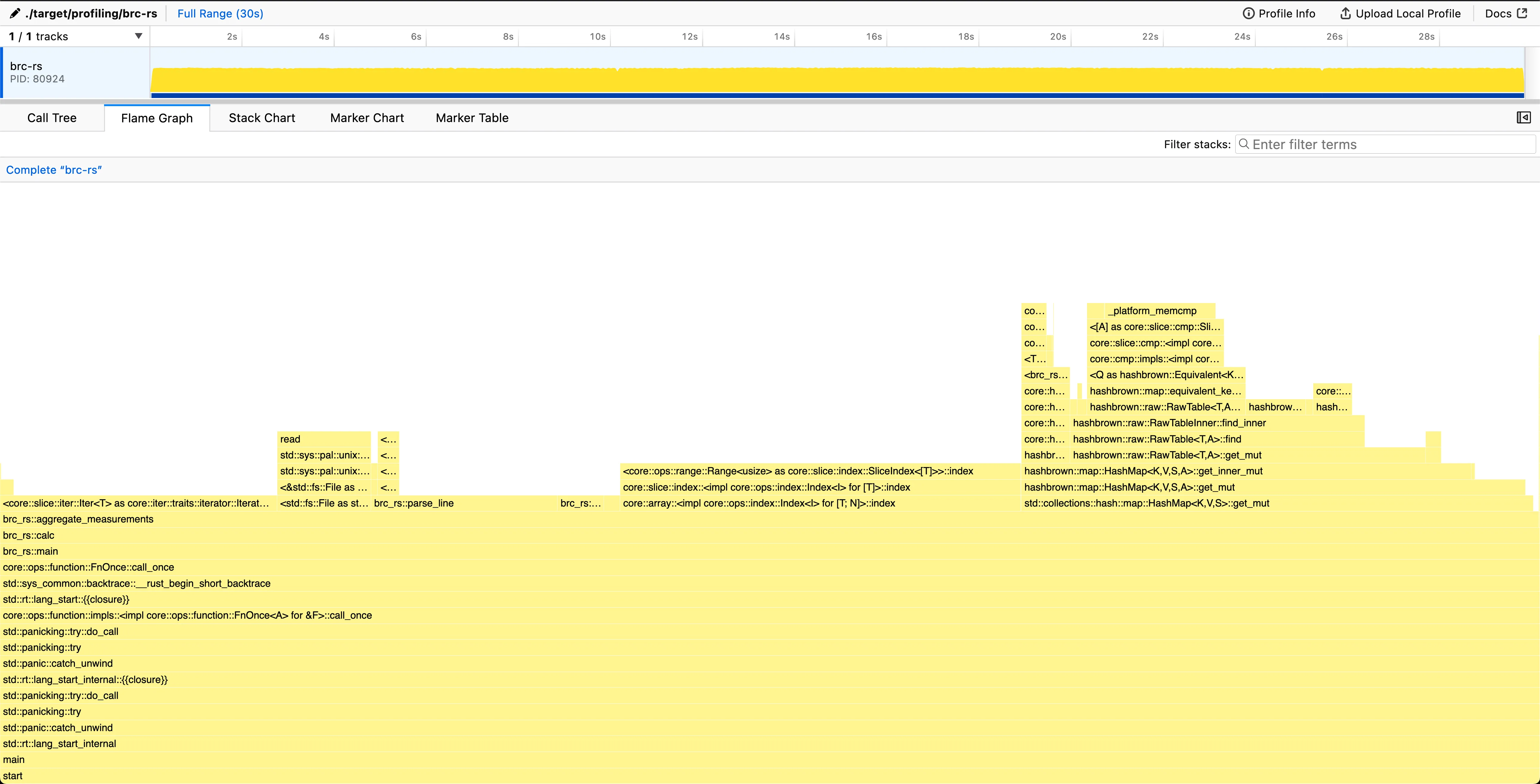
Now looking at the graph, the ~2-3s I/O blocking for the CPU usage has vanished from the chart. As we do the same amount of blocking I/O as previously, this means the blocking is distributed more evenly through the whole execution time.
Tweaking the CHUNK_SIZE
In the first chunked reader implementation, an arbitrary chunk size of 50 000 bytes was chosen. This can be thought of as a byte-interval, after we start reading the file again. With too small a chunk size, we start paying I/O overhead unnecessarily. After some testing, 500 000 bytes (0.5 MB) appears to be a better balance between I/O overhead and memory usage on an M1 Mac.
~/src/github/brc-rs (254edb8) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 28.663 s ± 0.546 s [User: 26.501 s, System: 1.259 s]
Range (min … max): 28.304 s … 29.631 s 5 runsMultithreading
We have now prepared our program to be able to handle multiple threads at once, and we can start utilizing them to speed up the program.
One might wonder why this wasn’t done earlier, but profiling and optimizing a single-threaded program is much more straightforward than a multithreaded one. As long as we keep the fact that we are going to use multiple threads in mind, we can optimize the single-threaded program to be as fast as possible, and then just spawn more threads to do the same work.
We need to somehow divide the work we have done sequentially into multiple threads. This can be achieved by dividing the file into chunks and then processing each chunk in a separate thread.
However, we need to be careful when creating the chunks, as we need to make sure that we don’t split the lines in the middle.
To do this, we can “peek into” the file at chunk_size, and then read forwards until we find a newline character.
Then set the next chunk to start after that newline character.
After creating the chunks, we can then spawn a thread for each chunk, and have them process the chunk in parallel.
After a thread is finished, it will insert its results into the shared hashmap, locked by a Mutex.
As we are using a Mutex, only one thread can access the hashmap at a time, blocking other threads from accessing it until the lock is released.
This lock contention isn’t a problem, as the amount of time spent holding the lock is minimal compared to the time spent processing data.
~/src/github/brc-rs (main*) » ./bench.sh
Benchmark 1: ./target/release/brc-rs
Time (mean ± σ): 3.747 s ± 0.093 s [User: 29.739 s, System: 2.102 s]
Range (min … max): 3.679 s … 3.910 s 5 runs As we can see from the flamegraph, the main thread is mostly waiting for the other threads to finish their work.
Other threads are then doing the actual work of reading the file and processing the data.
As we can see from the flamegraph, the main thread is mostly waiting for the other threads to finish their work.
Other threads are then doing the actual work of reading the file and processing the data.
Looking at the threads doing the processing, we can see that there are sections where some of the threads have 0% CPU usage. This is due to I/O blocking, as the thread is waiting for the file to be read into memory.
A slight trick to improve the I/O blocking nature was to create more chunks than there are threads available. This allows the OS scheduler to switch between threads, potentially enabling I/O blocked threads to be swapped to threads where I/O is not blocked.
Conclusion
The final result (for now) is a program that can process 1 billion rows in 3.7 seconds on a 10-core M1 MacBook Pro. This is a 97% improvement over the initial version.
A big chunk of the improvement came from multithreading in the end, but without the single-core optimizations first, we wouldn’t have been able to parallelize the program as effectively. Keeping the program single-threaded first allowed us to iterate on the program more easily.
The program is now utilizing all cores on the system, and the I/O blocking is distributed more evenly throughout the program. The memory footprint is kept low, and the program is now well optimized.
More optimizations could be done, for instance making line parsing branchless or using memory-mapped files, but the latter would require unsafe code or external crates, which were not in scope for this project.
For now, I’m happy with the result and will leave it here.